psql base
注意:这不是一个基础文档
从零开始-> visit: https://www.postgresqltutorial.com
安装
step0
https://www.postgresqltutorial.com/postgresql-getting-started/load-postgresql-sample-database/
https://juejin.cn/post/7219953605762875453
step1
brew install libpq
step2
由于 libpq 是 keg-only,Homebrew 不会自动将其链接到 /opt/homebrew/bin 目录中,这是为了避免与 postgresql 公式(formula)发生冲突。在这种情况下,如果你想要在任何地方都能使用 libpq 提供的命令(比如 psql),你需要手动将其可执行文件的路径添加到你的 PATH 环境变量中。
根据 Homebrew 提示的操作,你可以通过以下命令将 libpq 的 bin 目录添加到 PATH 中:
echo 'export PATH="/opt/homebrew/opt/libpq/bin:$PATH"' >> ~/.zshrc
这个命令会将一行添加到你的 ~/.zshrc 文件中(假设你使用的是默认的 zsh shell),这行内容会将 libpq 的 bin 目录添加到你的 PATH 环境变量中。添加这行之后,你需要重新加载 ~/.zshrc 文件或者重启终端来使更改生效。
要立即应用更改,你可以运行以下命令:
source ~/.zshrc
或者,你可以关闭当前的终端窗口并打开一个新的窗口。
完成这些步骤后,你应该能够在任何地方使用 libpq 提供的命令了,比如 psql。要验证是否成功,你可以运行:
psql --version
这应该会显示 psql 的版本信息。
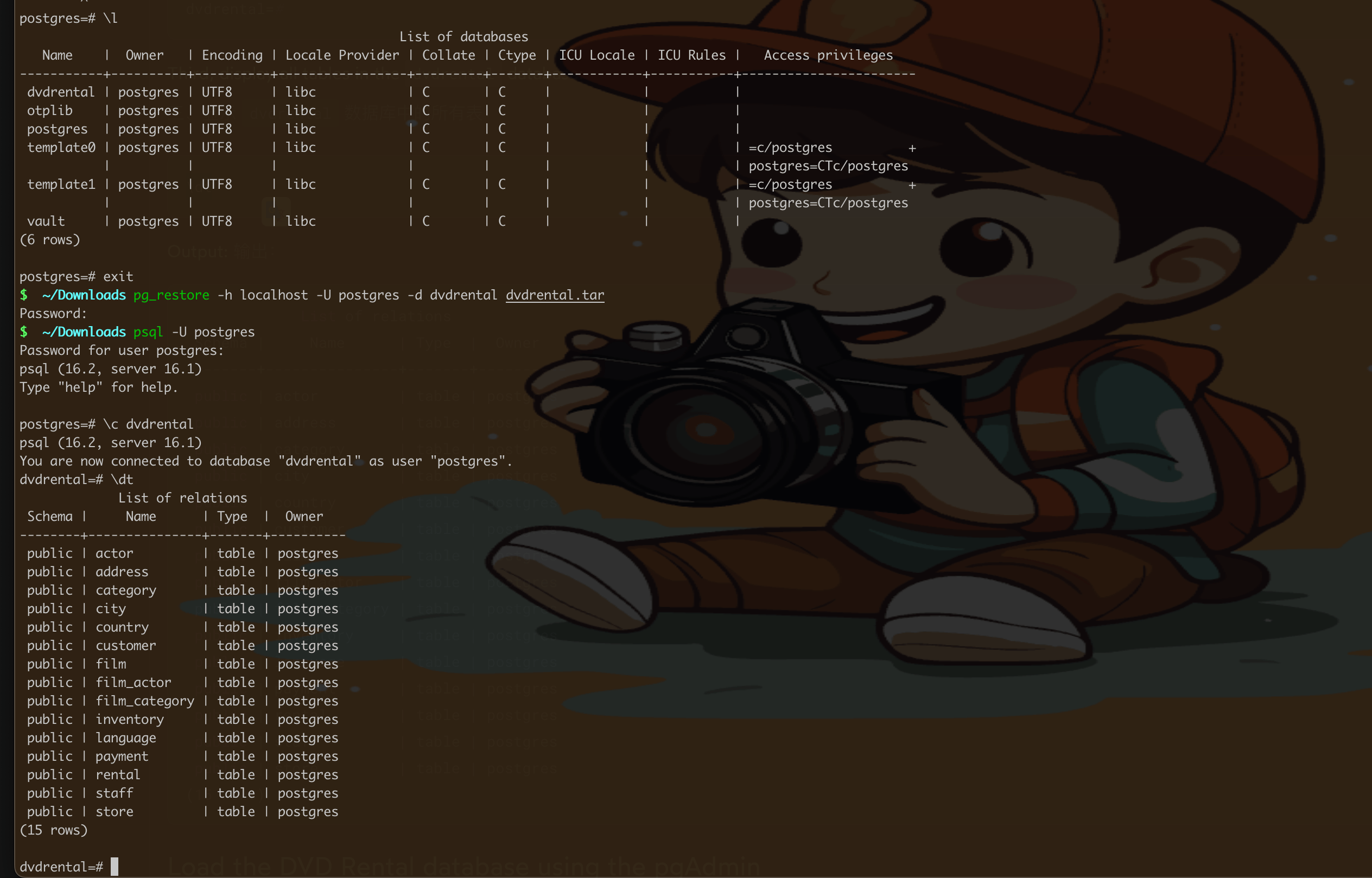
错误信息表明你尝试连接到 PostgreSQL 服务器时遇到了问题,因为 "dvdrental" 数据库不存在。这是一个常见的错误,发生在尝试连接到一个尚未创建的数据库时。
要解决这个问题,你需��要先创建名为 "dvdrental" 的数据库。你可以使用以下步骤:
-
确保你已经安装了 PostgreSQL 并且服务正在运行。
-
使用
psql命令行工具或其他 PostgreSQL 工具(如 pgAdmin)连接到 PostgreSQL 服务器。 -
连接到一个已经存在的数据库,比如默认的 "postgres" 数据库,因为你需要连接到数据库服务器才能创建新的数据库。在
psql中,你可以使用以下命令连接到 "postgres" 数据库:psql -U username -d postgres这里的
username是你的 PostgreSQL 用户名。 -
一旦连接到数据库服务器,你可以运行以下 SQL 命令来创建 "dvdrental" 数据库:
CREATE DATABASE dvdrental; -
如果你有 "dvdrental" 数据库的备份文件,并且想要恢复它,可以使用
pg_restore工具:pg_restore -U username -d dvdrental /path/to/dvdrental.backup确保替换
username为你的 PostgreSQL 用户名,以及/path/to/dvdrental.backup为备份文件的实际路径。
如果你不是数据库的管理员,你可能需要联系管理员来创建数据库或者给你相应的权限。如果你是管理员,但仍然遇到问题,可能需要检查 PostgreSQL 配置文件(如 postgresql.conf 和 pg_hba.conf)以确保正确设置了连接参数和权限。
链接
PostgreSQL FETCH 与 Limit
在 PostgreSQL 中,FETCH和LIMIT都用于限制查询结果集中的记录数,但它们的上下文和语法略有不同。
LIMIT子句是 SQL 标准的一部分,用于指定要从查询结果中返回的最大记录数。LIMIT通常��与OFFSET子句结合使用,后者指定要跳过的记录数。这种组合常用于实现分页功能。
下面是使用LIMIT的示例:
SELECT * FROM my_table LIMIT 10;
这将返回my_table中的前 10 条记录。
如果你还想跳过前面的一些记录,可以添加OFFSET:
SELECT * FROM my_table LIMIT 10 OFFSET 20;
这将跳过前 20 条记录,并返回之后的 10 条记录。
另一方面,FETCH子句是 SQL:2008 标准的一部分,通常与ORDER BY和OFFSET一起使用,作为CURSOR操作的一部分或在WINDOW函数中使用。FETCH在ORDER BY后面使用时,可以指定返回结果集的一个子集,这与LIMIT的功能相似。
下面是使用FETCH的示例:
SELECT * FROM my_table ORDER BY column_name OFFSET 20 ROWS FETCH FIRST 10 ROWS ONLY;
这个查询会跳过前 20 条记录,并返回之后的 10 条记录。这里的FETCH FIRST 10 ROWS ONLY与LIMIT 10类似,但它是在有ORDER BY和OFFSET子句存在的情况下使用的。
在实际使用中,LIMIT和OFFSET更加普遍,因为它们简洁且易于理解。然而,如果你正在使用 SQL 标准的较新版本,并且需要与标准保持一致,或者在使用CURSOR和WINDOW函数时,可能会使用FETCH。在功能上,它们在限制返回的记录数方面是等效的。
cast
连表查询
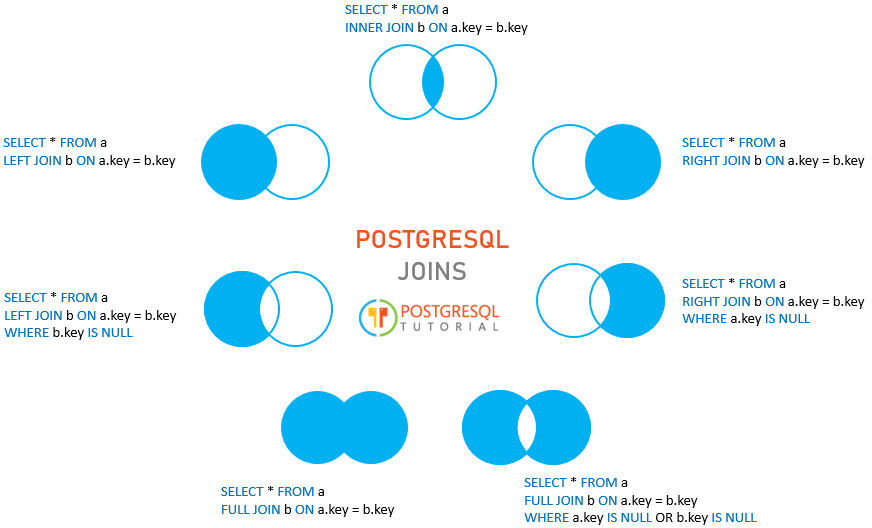
自然连接 vs 内连接
自然连接(NATURAL JOIN)确实是一种特殊类型的内连接(INNER JOIN),但它并不仅仅是内连接的简写。自然连接在行为上有一些特定的规则和特性,使其与标准的内连接有所区别。
自然连接的特点是它会自动连接两个表中具有相同名称的所有列。它��不需要显式指定连接条件。自然连接只包括两个表共有的列,并且这些共有列的值必须相等。在结果集中,这些共有列只会出现一次,避免了重复。
这里有一个简单的例子来展示自然连接和内连接的区别:
假设有两个表,employees 和 departments:
employees 表:
+------------+-----------+------------+
| employee_id| name | department |
+------------+-----------+------------+
| 1 | Alice | Sales |
| 2 | Bob | Marketing |
+------------+-----------+------------+
departments 表:
+------------+------------+
| department | location |
+------------+------------+
| Sales | New York |
| Engineering| San Jose |
+------------+------------+
使用内连接(INNER JOIN)时,你需要显式指定连接条件:
SELECT *
FROM employees
INNER JOIN departments
ON employees.department = departments.department;
这将返回:
+------------+------+------------+------------+----------+
| employee_id| name | department | department | location |
+------------+------+------------+------------+----------+
| 1 | Alice| Sales | Sales | New York |
+------------+------+------------+------------+----------+
注意结果中的department列出现了两次。
而使用自然连接(NATURAL JOIN)时,你不需要指定连接条件,数据库系统会自动连接两个表中名称相同的列:
SELECT *
FROM employees
NATURAL JOIN departments;
这将返回:
+------------+------+------------+----------+
| employee_id| name | department | location |
+------------+------+------------+----------+
| 1 | Alice| Sales | New York |
+------------+------+------------+----------+
在这个例子中,department列只出现一次,因为自然连接自动处理了列名匹配并合并了重复的列。
自然连接可以简化查询,但它也可能导致一些不明确或不可预见的行为,特别是当两个表中有多个名称相同的列但实际上不是用于连接的列时。因此,在使用自然连接时需要谨慎,确保你完全理解它的行为以及它如何适用于你的数据模型。
HAVING vs WHERE
在 SQL 中,WHERE和HAVING子句都用于过滤返回的数据,但它们在查询中的作用和使用时机有所不同。以下是WHERE和HAVING子句的主要区别:
WHERE 子句
WHERE子句用于过滤行数据,即在聚合操作之前对数据进行筛选。- 它作用于单个行,根据指定的条件筛选出满足条件的行。
WHERE子句不能与聚合函数一起使用,因为它在数据被聚合前进行过滤。WHERE子句在分组(GROUP BY)之前应用。
例如:
SELECT *
FROM employees
WHERE department = 'Sales';
这个查询返回employees表中属于销售部门的所有员工。
HAVING 子句
HAVING子句用于过滤聚合后的数据,即在聚合操作之后对数据进行筛选。- 它作用于分组后的数据集,根据指定的条件筛选出满足条件的分组。
HAVING子句通常与聚合函数(如SUM(),AVG(),COUNT()等)一起使用。HAVING子句在分组(GROUP BY)之后应用。
例如:
SELECT department, COUNT(*)
FROM employees
GROUP BY department
HAVING COUNT(*) > 5;
这个查询返回拥有超过 5 名员工的部门及其员工数量。
总结
- 使用
WHERE子句在分组前过滤行。 - 使用
HAVING�子句在分组后过滤组。
WHERE和HAVING可以在同一个查询中同时使用,WHERE先筛选行,然后GROUP BY进行分组,最后HAVING筛选分组。这样做可以提高查询效率,因为通过WHERE子句减少了需要分组的数据量。
相关子查询 vs 子查询
在 SQL 中,"相关子查询"和"子查询"都是在一个查询内部包含另一个查询的情况,但它们的工作方式和用途有所不同。
子查询
子查询是指嵌套在另一个查询中的查询。子查询可以出现在 SELECT、FROM、WHERE 等子句中。子查询通常是独立的,这意味着子查询可以独立于外部查询执行,并且其执行结果可以作为一个值或一组值,供外部查询使用。
示例:
SELECT employee_id, name
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
在这个例子中,子查询(SELECT AVG(salary) FROM employees)计算所有员工的平均工资,然后外部查询使用这个结果来找出工资高于平均值的员工。子查询是独立的,因为它不依赖于外部查询的任何值。
相关子查询
相关子查询是一种特殊类型的子查询,它在执行时依赖于外部查询的行。每一行外部查询的数据都可能影响相关子查询的结果。因此,相关子查询可能需要为外部查询的每一行执行一次。
示例:
SELECT e1.employee_id, e1.name
FROM employees e1
WHERE e1.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e1.department_id = e2.department_id
);
在这个例子中,相关子查询计算的是每个部门的平均工资,并且外部查询使用这个结果来找出在各自部门中工资高于平均值的员工。相关子查询(SELECT AVG(e2.salary) FROM employees e2 WHERE e1.department_id = e2.department_id)依赖于外部查询中的e1.department_id值。
总结
- 子查询:通常是独立的,不依赖于外部查询的行,可以单独执行。
- 相关子查询:依赖于外部查询的行,通常对于外部查询的每一行执行一次,通常更复杂且可能性能较低。
相关子查询在执行时通常比普通子查询更为耗时,因为它可能需要对外部查询的每一行都执行一次。然而,相关子查询在处理某些类型的问题时非常有用,例如,当你需要对比每个分组内的数据时。在设计查询时,应该尽可能地使用独立子查询,因为它们通常执行得更快。但在某些情况下,只有相关子查询能够提供所需的结果。
优化相关子查询
直接第一遍查询查询出每个部门的平均工资,第二遍查询,查询比平均工资高的员工? 是的,您提到的方法是一种优化策略,通过将查询分解为两个步骤来避免对于每一行外部查询都执行一次相关子查询。这种方法可以使用临时表或者公用表表达式(Common Table Expressions, CTEs)来实现。
使用 CTE 的 SQL 查询可能如下所示:
WITH DepartmentAverage AS (
SELECT department_id, AVG(salary) AS AvgSalary
FROM employees
GROUP BY department_id
)
SELECT e.employee_id, e.name, e.salary
FROM employees e
INNER JOIN DepartmentAverage da ON e.department_id = da.department_id
WHERE e.salary > da.AvgSalary;
在这个例子中,首先使用WITH关键字创建了一个 CTE DepartmentAverage,它计算每个部门的平均工资。然后,在主查询中,我们通过INNER JOIN将员工表与 CTE 连接起来,并在WHERE子句中筛选出那些工资高于其部门平均工资的员工。
这种方法通常比相关子查询更有效率,因为它避免了对每个员工行都执行子查询的情况。CTE 或者临时表只计算一次,然后在主查询中被重复使用。
请注意,不同的数据库系统在执行计划和优化方面有不同的行为,有时数据库的查询优化器能够将相关子查询自动优化为更高效的执行计划。因此,在实际应用中,建议分析查询的执行计划来确定最佳的查询策略。
Section 7. Subquery
如何区分一个查询是不是行级别的子查询
作为新手,要区分一个查询是否为行级别的子查询,可以通过以下几个特征来判断:
-
相关性:行级别的子查询通常与外部查询相关联,这意味着子查询中的条件依赖于外部查询的当前行。在子查询中,你会发现对外部查询中的列的引用。
-
位置:行级别的子查询可以出现在
SELECT,WHERE, 或者HAVING子句中。它们通常用于为每一行生成或过滤数据。 -
单行或多行比较:行级别的子查询可能用于比较单行或多行的结果。例如,使用
EXISTS,IN,ANY,ALL等关键字时,子查询与外部查询的每一行进行比较。 -
返回值:行级别的子查询不一定返回一个具体的数据值,它可能只是用于检查条件是否成立(如使用
EXISTS)。
来看两个例子,帮助你理解行级别的子查询:
例子 1:使用相关子查询
SELECT c.customer_name,
(SELECT COUNT(*)
FROM orders o
WHERE o.customer_id = c.customer_id) as order_count
FROM customer c;
在这个例子中,子查询计算每个客户的订单数量。子查询依赖于外部查询的customer_id,这是一个行级别的子查询。
例子 2:使用EXISTS
SELECT c.customer_name
FROM customer c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
AND o.order_date > '2021-01-01'
);
这里,子查询检查是否存在在特定日期之后的订单。子查询中的o.customer_id = c.customer_id表��明它是相关的,并且为行级别的子查询。
如果你看到一个子查询是在处理外部查询的每一行数据,并且子查询中包含了外部查询的列引用,那么这通常是一个行级别的子查询。如果子查询是独立的,没有引用外部查询的列,那么它可能是一个标量子查询或一个独立的查询,而不是行级别的。
为什么行级子查询看起来那么乱
行级别的子查询可能给新手带来混淆,原因通常包括以下几点:
-
复杂性:行级别的子查询通常涉及多层查询,其中内层查询依赖于外层查询的结果。这种依赖关系需要对 SQL 有更深入的理解。
-
相关性:行级别的子查询经常引用外部查询中的列,这种相关性(correlation)需要在理解上下文的同时跟踪列的来源和作用。
-
性能考虑:行级别的子查询可能会对查询性能产生不利影响,尤其是在处理大量数据时。这可能导致查询执行计划变得复杂,增加了理解和优化查询的难度。
-
多个查询层次:在一个查询中嵌套多个子查询会使得 SQL 语句的层次结构变得复杂,尤其是当这些子查询彼此之间还有相关性时。
-
阅读和调试困难:由于子查询可能嵌套在其他子查询之内,这使得阅读和调试 SQL 语句变得更加困难,因为需要逐层理解每个子查询的逻辑和目的。
-
逻辑复杂:行级别的子查询可能涉及复杂的逻辑,需要仔细分析每�一行数据如何影响子查询的结果,以及这些结果如何反过来影响最终的输出。
为了更好地理解和管理行级别的子查询,可以采取以下措施:
- 逐步分解:尝试分解复杂的查询,单独运行子查询部分,以便理解其如何对每一行数据进行操作。
- 注释和文档:为查询添加注释,解释每个子查询的目的和它是如何与外部查询相关联的。
- 查询格式化:使用适当的缩进和格式化,使 SQL 语句的结构更加清晰。
- 学习和实践:通过学习和实践来提高对 SQL 的理解,包括子查询的使用和优化。
- 使用视图或 CTE:考虑使用视图(View)或公用表表达式(Common Table Expressions,CTE)来简化复杂的子查询。
随着经验的积累,对行级别子查询的理解将会提高,SQL 语句的阅读和编写也会变得更加自然。
example
SELECT
first_name,
last_name
FROM
customer c
WHERE
EXISTS (
SELECT
1
FROM
payment p
WHERE
p.customer_id = c.customer_id
AND amount > 11
)
ORDER BY
first_name,
last_name;
这个 SQL 查询的意思略有不同。这段代码的目的是从customer表中选择那些至少有一条在payment表中金额超过 11 的记录的客户的first_name和last_name。EXISTS关键字用于检查一个子查询是否返回至少一行数据。
以下是对这个查询的逐步解释:
-
SELECT first_name, last_name FROM customer c:这部分是主查询,它指示要从customer表中选择first_name和last_name列。 -
WHERE EXISTS (...):这是一个条件,用于过滤只有满足括号内子查询条件的customer记录。 -
子查询:
SELECT 1 FROM payment p WHERE p.customer_id = c.customer_id AND amount > 11:这是一个子查询,它在payment表中为每个正在考虑的customer记录查找匹配的payment记录。SELECT 1:这里选择数字 1 是一个常用的技巧,因为在EXISTS子查询中,只关心是否有行满足条件,而不关心行的内容。p.customer_id = c.customer_id:这是一个关联条件,将payment表中的customer_id与当前考虑的customer表中的customer_id相匹配。AND amount > 11:这是子查询的过滤条件,它只选择那些支付金额超过 11 的payment记录。
-
ORDER BY first_name, last_name:这是主查询的排序条件,指示查询结果应按照first_name升序排列,在first_name相同的情况下,再按照last_name升序排列。
综上所述,这个查询返回的是那些至少有一次支付金额超过 11 的客户的名字,并按照名字进行排序。这不是在找“数量是 11 的”,而是在找支付金额大于 11 的记录。
为什么 amount 没有写成 p.amount?
在 SQL 查询中,当你引用表中的列时,如果列名在查询涉及的所有表中是唯一的,那么可以省略表名或表的别名。在你给出的查询中,amount 这个列名很可能在 payment 表中是唯一的,也就是说,customer 表中没有名为 amount 的列。因此,即使没有明确写出 p.amount,数据库仍然能够明白你指的是 payment 表中的 amount 列。
不过,明确指定列的完整名称(包括表名或表的别名)是一个好习惯,因为这样可以提高 SQL 代码的可读性和清晰度,尤其是在涉及多个表且表之间有相同列名的情况下。如果 amount 列同时存在于 customer 和 payment 表中,那么就必须使用 p.amount 来消除歧义。
在你提供的查询中,省略了 p. 前缀,这不会影响查询的功能,但添加上 p. 可以使得 SQL 语句更加明确和健壮。
请注意,如果子查询返回 NULL ,则 EXISTS 运算符返回 true
Section 8. Common Table Expressions 使用 CTE 的递归查询 🚗
WITH RECURSIVE subordinates AS (
SELECT
employee_id,
manager_id,
full_name
FROM
employees
WHERE
employee_id = 2
UNION
SELECT
e.employee_id,
e.manager_id,
e.full_name
FROM
employees e
INNER JOIN subordinates s ON s.employee_id = e.manager_id
)
SELECT * FROM subordinates;
抱歉,我没有清楚地解释 UNION 在递归 CTE 中的作用。在递归公用表表达式中,UNION 或 UNION ALL 用于合并初始查询(递归的种子部分)的结果和递归部分的结果。在您提供的代码中,UNION 是用来将每一轮递归查询的结果合并起来的。下面是对您的代码的详细解释,包括 UNION 的作用:
-
递归种子查询: 这是递归开始的地方,它选取了
employee_id为 2 的员工。SELECT
employee_id,
manager_id,
full_name
FROM
employees
WHERE
employee_id = 2 -
递归步骤: 这部分是递归查询,它参考了 CTE
subordinates中已经存在的结果,并试图找到与这些结果的employee_id匹配的manager_id的员工。SELECT
e.employee_id,
e.manager_id,
e.full_name
FROM
employees e
INNER JOIN subordinates s ON s.employee_id = e.manager_id -
递归查询的组合:
UNION关键字用于合并种子查询的结果和递归步骤的结果。在这个例子中,应该使用UNION ALL而不是UNION,因为UNION会消除重复的行,而在递归查询中我们通常不期望消除重复行,因为每一轮递归的结果都是独立的。如果使用UNION,可能会意外地删除有效的数据行,因为UNION在合并结果时会检查重复的行并将它们删除。UNION ALL -
递归终止: 递归查询会继续执行,直到没有新的行可以添加到结果集中为止。在这个例子中,递归会在没有员工的
manager_id与结果集中任何employee_id匹配时停止。 -
结果返回: 最后,
SELECT * FROM subordinates;返回了包含初始员工和所有下属(包括下属的下属等)的最终结果集。
在您的代码中,应该使用 UNION ALL 而不是 UNION,除非您有特别的理由要移除重复的行。如果您的意图是包含所有下属(即使有重复),则应该这样写:
WITH RECURSIVE subordinates AS (
SELECT
employee_id,
manager_id,
full_name
FROM
employees
WHERE
employee_id = 2
UNION ALL
SELECT
e.employee_id,
e.manager_id,
e.full_name
FROM
employees e
INNER JOIN subordinates s ON s.employee_id = e.manager_id
)
SELECT * FROM subordinates;
使用 UNION ALL 确保了所有递归步骤的结果都被包括在内,而不会有任何行被移除。
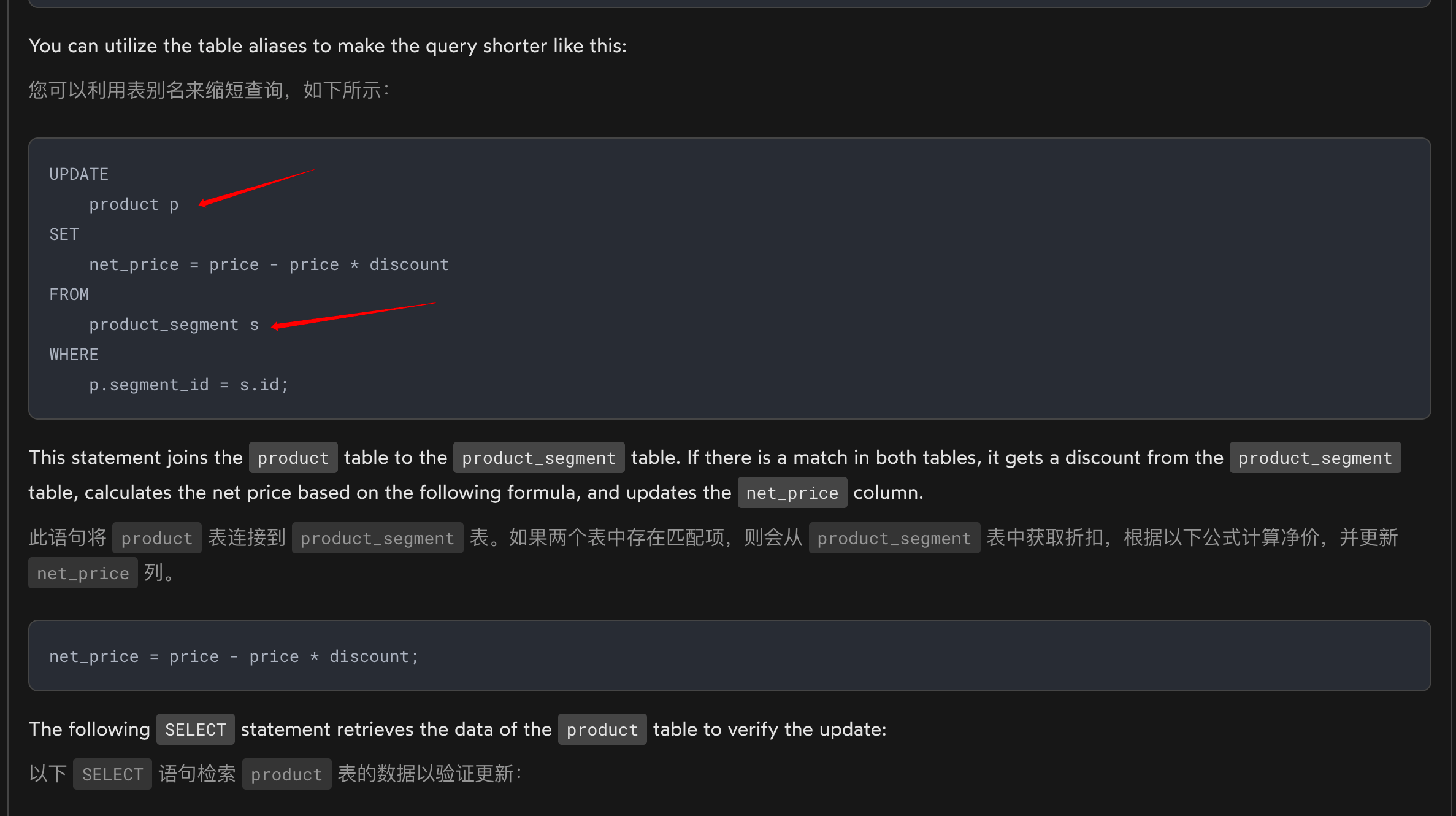
Update join
- 有时,您需要根据另一个表中的值更新表中的数据。在这种情况下,您可以使用 PostgreSQL UPDATE JOIN
- 要在 UPDATE 语句中将表 (table1) 与另一个表 (table2) 连接,请在 FROM 子句中指定连接表 (table2),并在 < b2> 子句。 FROM 子句必须紧接在 SET 子句之�后出现。
Transaction
-- start a transaction
BEGIN;
-- insert a new row into the accounts table
INSERT INTO accounts(name,balance)
VALUES('Alice',10000);
-- commit the change (or roll it back later)
COMMIT;
---
注意
psql 将 NULL 显示为空字符串
psql 将 NULL 显示为空字符串。要更改 psql 在终端中显示 null 的方式,可以使用命令: \pset null null
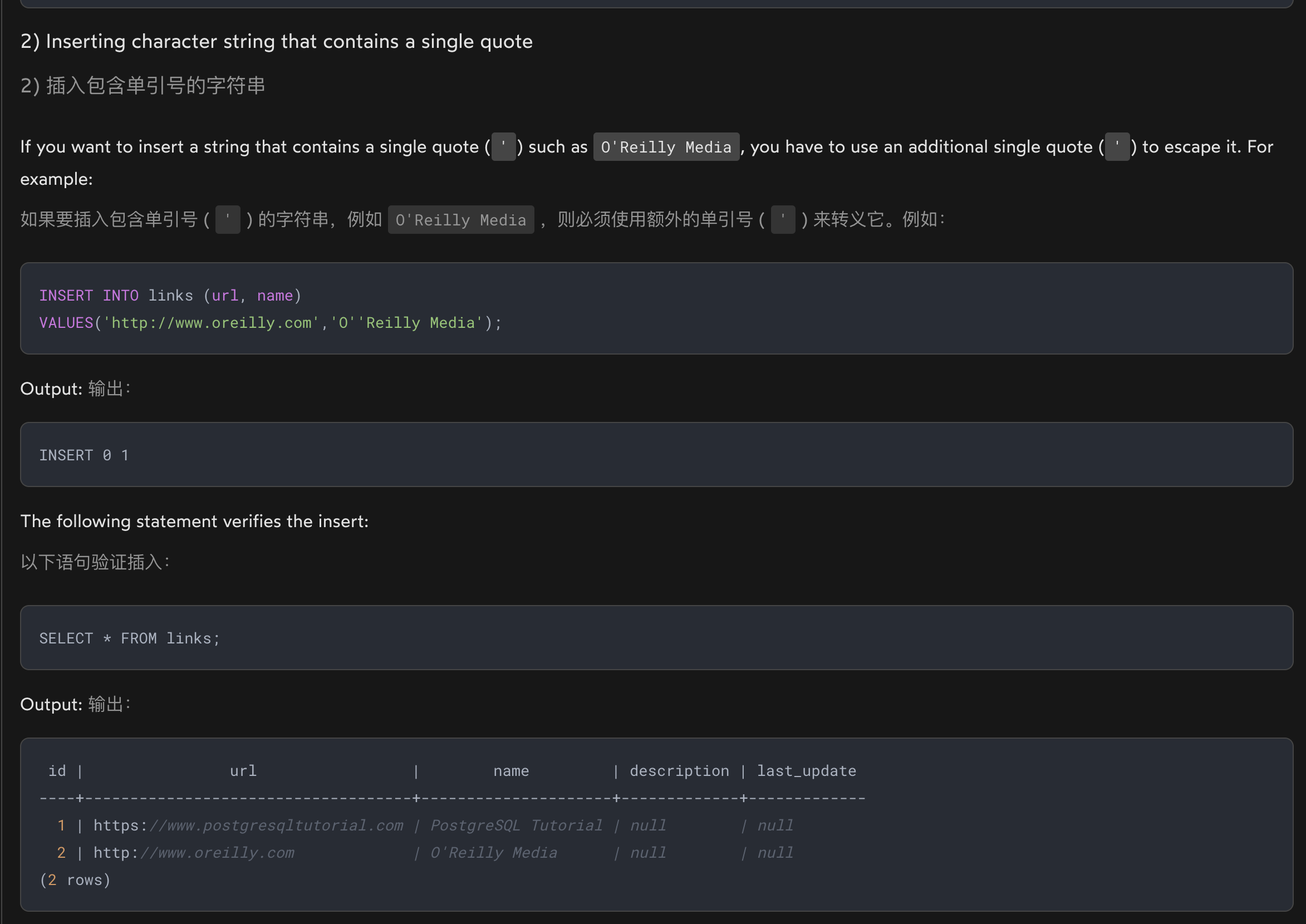
插入包含单引号的字符串
如果要插入包含单引号 ( ' ) 的字符串,例如 O'Reilly Media ,则必须使用额外的单引号 ( ' ) 来转义它
https://www.postgresqltutorial.com/postgresql-tutorial/postgresql-insert/
Upsert 🚗
INSERT INTO inventory (id, name, price, quantity)
VALUES (1, 'A', 16.99, 120)
ON CONFLICT(id)
DO UPDATE SET
price = EXCLUDED.price, -- EXCLUDED引用尝试插入的行的值
quantity = EXCLUDED.quantity;
在这个 INSERT 语句中,EXCLUDED 关键字是用在 ON CONFLICT 子句中,这个子句是 PostgreSQL 中处理冲突(即违反唯一约束)的一种方式。在这种情况下,如果��尝试插入的行违反了某个唯一约束(在这个例子中是 id 字段),则不会执行插入操作,而是执行 ON CONFLICT 子句中指定的替代操作。
在 DO UPDATE SET 部分,EXCLUDED 用来引用原本尝试插入但因为冲突而被排除的行的值。所以,如果在 id 字段上发生冲突,那么:
EXCLUDED.price指的是尝试插入的语句中的price值(16.99)。EXCLUDED.quantity指的是尝试插入的语句中的quantity值(120)。
因此,如果发生冲突,那么已存在的记录将会被更新,其 price 和 quantity 字段的值将会被设置为尝试插入的记录中对应的值。
下面是完整的解释:
- 如果
id为 1 的记录不存在,那么将插入新行(id=1, name='A', price=16.99, quantity=120)。 - 如果
id为 1 的记录已经存在,那么这条记录的price和quantity字段将会被更新为EXCLUDED中的值,即尝试插入的新值(price=16.99, quantity=120),而name字段不会被更新。
此语法是 PostgreSQL 的 UPSERT 操作的一部分,允许你在唯一约束冲突时执行更新操作。
true/false 值有哪些

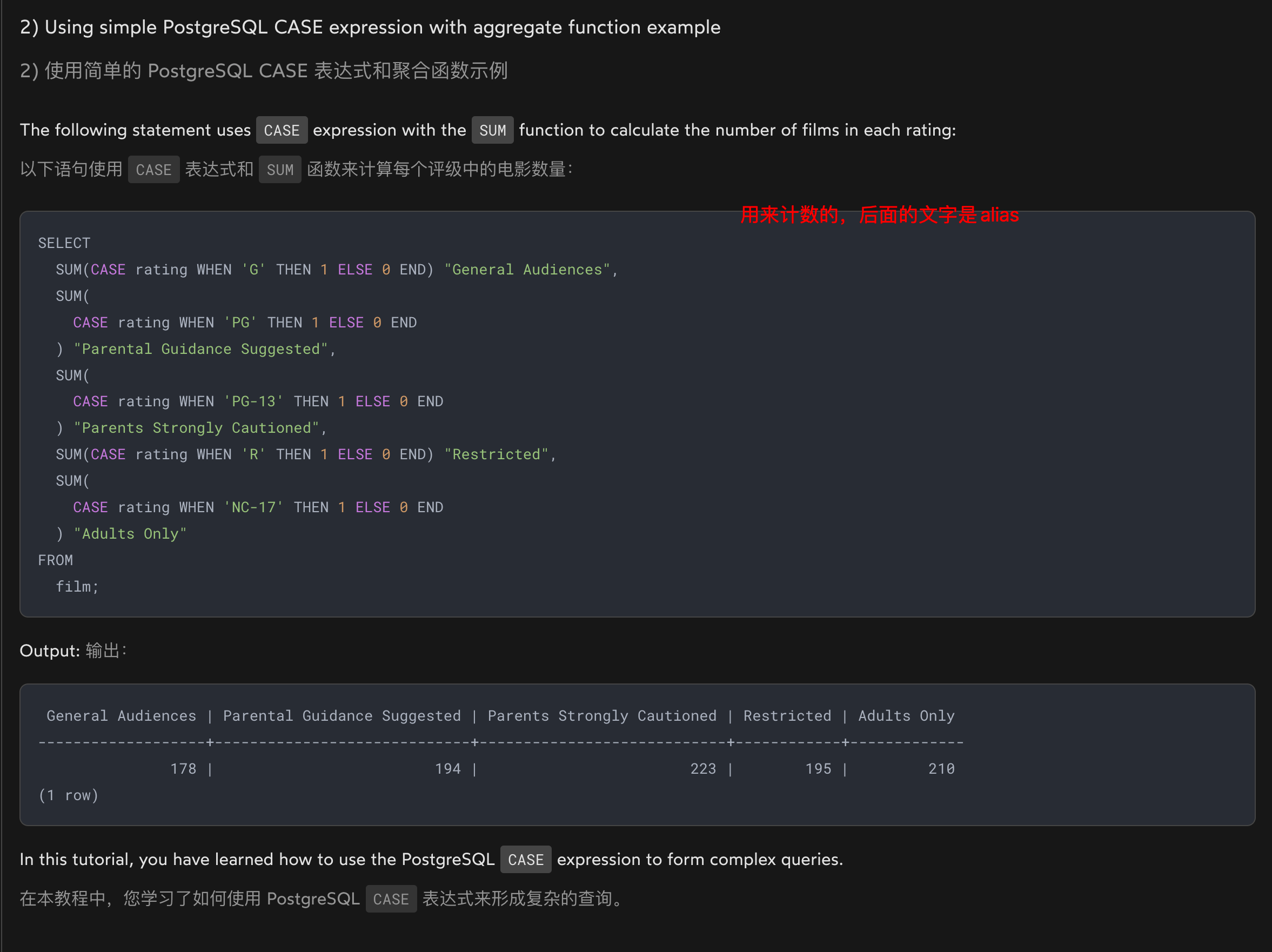
CASE & SUM
SELECT
SUM(CASE rating WHEN 'G' THEN 1 ELSE 0 END) "General Audiences",
SUM(
CASE rating WHEN 'PG' THEN 1 ELSE 0 END
) "Parental Guidance Suggested",
SUM(
CASE rating WHEN 'PG-13' THEN 1 ELSE 0 END
) "Parents Strongly Cautioned",
SUM(CASE rating WHEN 'R' THEN 1 ELSE 0 END) "Restricted",
SUM(
CASE rating WHEN 'NC-17' THEN 1 ELSE 0 END
) "Adults Only"
FROM
film;
在您提供的 SQL 查询中,SUM 函数被用来计算每种电影分级(rating)的总数。CASE 语句在这里用作条件计数器,为每个满足特定条件的行提供值 1,否则提供 0。
这是如何工作的:
- 对于每一行,
CASE语句检查rating列的值。 - 如果
rating列的值匹配CASE语句中的WHEN条件(例如'G'、'PG'、'PG-13'、'R'或'NC-17'),则CASE语句的结果是1。 - 如果
rating列的值不匹配任何WHEN条件,则CASE语句的结果是0。 SUM函数然后对每个分组的结果进行求和。由于1表示一个匹配的行,所以对所有的1求和实际上就是计算匹配特定rating的行数。
因此,查询的结果是每种电影分级的电影数量的总和,分别列出了 G 级、PG 级、PG-13 级、R 级和 NC-17 级电影的数量。这种方法避免了对每种分级执行单独的查询,提高了效率,因为它在单个查询中完成了所有的计算。
除以 NULL 将返回 NULL
QA
sql 返回的结果集就是一张临时表?
在 SQL 中,查询返回的结果集可以被视为一个临时的、只读的表。这个结果集是由查询从数据库中检索出的数据组成的,它具有自己的列和行,就像数据库中的实际表一样。然而,这个结果集并不是数据库结构的一部分,它不会被存储为一个持久的表,而是在查询执行时动态生成的。
你可以对这个结果集进行操作,就像对表进行操作一样,例如排序 (ORDER BY)、过滤 (WHERE)、聚合 (GROUP BY) 等。在某些数据库系统中,你还可以将这个结果集作为一个派生表(或内联视图)在更大的查询中使用,或者将它存储在一个临时表中,以便在事务或会话的生命周期内重复使用。
总的来说,虽然 SQL 查询返回的结果集在概念上类似于一张表,但它是临时的,并且通常只存在于查询执行的上下文中。
先 where 后 ORDER BY
是的,这两个查询有本质的区别,第二个查询实际上是无效的。
在 SQL 语法中,ORDER BY子句必须位于WHERE子句之后,因为WHERE子句用于过滤数据,而ORDER BY子句用于对结果进行排序。如果你将ORDER BY放在WHERE子句之前,查询将不会执行,并且会产生一个语法错误。
正确的查询应该是这样的:
SELECT
film_id,
title
FROM
film
WHERE
film_id NOT IN (1, 2, 3)
ORDER BY
film_id;
这个查询会从film表中选择所有film_id不是 1、2、3 的记录,并按film_id进行排序。
如果你尝试执行第二个查询:
SELECT
film_id,
title
FROM
film
ORDER BY
film_id
WHERE
film_id NOT IN (1, 2, 3);
数据库会返回一个错误,因为WHERE子句必须出现在ORDER BY子句之前。正确的查询顺序应该是先过滤(使用WHERE),然后排序(使用ORDER BY)。
关系表 vs 视图表
在数据库管理系统中,视图表(View)和关系表(Table)是两种不同的数据结构,它们在用途和性质上有所区别。
关系表(Table):
- 关系表是数据库中存储数据的基本结构,它是由行(记录)和列(字段)组成的集合。
- 表中的数据是物理存储在数据库中的,每一行代表一个数据记录,每一列代表该记录的一个属性。
- 表是数据库的核心组成部分,用于持久存储数据。
- 关系表通常被简称为表。
视图表(View):
- 视图是一个虚拟表,其内容由查询定义。它是一种逻辑上的表现,基于一个或多个实际表中的数据。
- 视图本身不存储数据,它是通过对一个或多个表执行的查询的结果集的表现形式。
- 视图可以用来简化复杂的查询,隐藏数据的复杂性��,限制对数据的访问,或者展现数据的特定部分。
- 视图通常被用作安全机制,允许用户访问特定的数据而不是整个表的数据。
- 视图可以被查询和更新(如果视图是可更新的),就像表一样。
总结来说,关系表是实际存在于数据库中存储数据的结构,而视图表是基于表中数据的一个虚拟展现,它通过查询定义,并在查询时动态生成。视图为用户提供了一种自定义数据展现和操作数据的方式,而不需要修改底层的物理表结构。
sql 是什么意思
在 SQL 语句中,FOREIGN KEY 约束用于指定两个表之间的关系,确保参照完整性。具体到您提供的例子:
FOREIGN KEY (order_id)
REFERENCES orders(order_id) ON DELETE CASCADE ON UPDATE CASCADE,
/*
CREATE TABLE orders(
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(255) NOT NULL,
ordered_date DATE NOT NULL,
status VARCHAR(20) NOT NULL
);
CREATE TABLE order_items (
item_id INT NOT NULL,
product_name VARCHAR(255) NOT NULL,
quantity INT NOT NULL,
order_id INT NOT NULL,
FOREIGN KEY (order_id)
REFERENCES orders(order_id) ON DELETE CASCADE ON UPDATE CASCADE,
PRIMARY KEY (order_id, item_id)
);
INSERT INTO orders (customer_name, ordered_date, status)
VALUES
('John Doe', '2024-01-25', 'Processing'),
('Jane Smith', '2024-01-26', 'Shipped'),
('Bob Johnson', '2024-01-27', 'Delivered');
INSERT INTO order_items (order_id, item_id, product_name, quantity)
VALUES
(1, 1, 'A', 2),
(1, 2, 'B', 1),
(2, 1, 'C', 3),
(3, 1, 'D', 5),
(3, 2, 'E', 2); */
这段代码的意思是:
-
FOREIGN KEY (order_id): 这指定了当前表中的order_id列作为外键。 -
REFERENCES orders(order_id): 这定义了外键的参照关系,即当前表的order_id列引用了orders表的order_id列。这意味着在当前表中的每个order_id值必须在orders表的order_id列中存在。 -
ON DELETE CASCADE: 这意味着如果在orders表中删除了某个order_id的记录,那么在当前表中所有包含这个order_id的记录也会被自动删除。这是级联删除的行为,用于确保数据的一致性。 -
ON UPDATE CASCADE: 这意味着如果在orders表中更新了某个order_id的值,那么在当前表中所有引用这个order_id的记录也会跟着更新为新的值。这是级联更新的行为,同样是为了保持数据的一致性。
总之,这段代码定义了一个外键约束,确保了当前表中的 order_id 与 orders 表中的 order_id 保持引用关系,并且在 orders 表中 order_id 的删除或更新操作会级联到当前表中相应的记录。这有助于自动维护数据的完整性,避免出现孤立的记录。
约束就是勾子,在执行的时候会进行附加的操作
约束(Constraint)在数据库中确实可以类似于“勾子”(Hook)的概念,它们在执行数据库操作时会触发附加的规则检查或行为。约束用于强制执行数据库的数据完整性和一致性规则。以下是一些常见的数据库约束类型及其作用:
-
PRIMARY KEY: 用于唯一标识表中的每一行,并且保证该列不包含空值。
-
FOREIGN KEY: 用于确保一个表中的数据与另一个表的数据相匹配,建立表之间的关联关系。
-
UNIQUE: 保证列中的所有值都是不同的,即在该列上不能有重复值。
-
NOT NULL: 保证列中的每一行都必须有值,不允许空值。
-
CHECK: 保证列中的值满足特定的条件,例如年龄必须大于 18。
-
DEFAULT: 当插入记录时如果没有指定某列的值,列会取默认值。
在你之前提到的 ON DELETE CASCADE 和 ON UPDATE CASCADE 约束中,这些“勾子”在删除或更新操作发生时触发,进行级联删除或更新,以保持数据的引用完整性。
因此,虽然数据库约束不是传统编程中的“勾子”,它们确实在数据库操作中起到了类似的作用,自动执行定义好的规则,以确保数据的有效性和一致性。
如果使用 check 约束,如何给前端正确返回错误信息?
当使用 CHECK 约束在数据库层面强制数据满足特定条件时,如果违反了这些约束,数据库通常会抛出一个错误。前端应用程序需要捕捉这个错误,并将其转换为用户友好的信息。
以下是处理这种情况的一般步骤:
-
捕捉错误: 在后端代码中,当执行数据库操作(如插入或更新)时,使用错误处理机制捕捉可能抛出的异常。
-
解析错误信息: 捕捉到异常后,解析错误信息以确定是否由
CHECK约束违反引起。不同的数据库系统可能会返回不同格式的错误信息。 -
定制响应: 根据捕捉到的错误,定制一个适当的响应消息。这个消息应该是用户友好的,不应该直接将数据库错误暴露给用户,因为这可能包含敏感信息,而且对于非技术用户来说可能难以理解。
-
返回响应: 将定制的错误消息作为响应返回给前端应用程序。可以通过 HTTP 状态码(如 400 Bad Request)和一个清晰的错误消息来实现。
-
前端处理: 前端应用程序接收到后端的响应后,根据返回的错误消息提示用户,或者引导�用户采取适当的操作来纠正数据。
以下是一个简化的后端伪代码例子,展示了如何捕捉和处理数据库错误:
from flask import Flask, jsonify, request
from sqlalchemy.exc import IntegrityError
app = Flask(__name__)
@app.route('/add_user', methods=['POST'])
def add_user():
try:
# 假设这里是插入用户数据到数据库的逻辑
# insert_user_to_db(request.form)
pass
except IntegrityError as e:
# 解析错误信息
error_info = str(e.orig)
if 'CHECK constraint failed' in error_info:
# 定制用户友好的错误消息
user_friendly_message = '输入的数据不满足要求,请检查后重新提交。'
# 返回定制的错误消息和400状态码
return jsonify({'error': user_friendly_message}), 400
else:
# 其他数据库�错误
return jsonify({'error': '数据库错误,请联系管理员。'}), 500
else:
# 如果没有错误,返回成功消息
return jsonify({'message': '用户添加成功'}), 201
# 启动 Flask 应用程序...
在前端,你可以使用 JavaScript 来处理这些响应,并相应地更新用户界面。例如:
fetch('/add_user', {
method: 'POST',
body: JSON.stringify(userData),
headers: {
'Content-Type': 'application/json',
},
})
.then((response) => response.json())
.then((data) => {
if (data.error) {
// 显示错误消息给用户
alert(data.error);
} else {
// 显示成功消息
alert(data.message);
}
})
.catch((error) => {
// 处理网络错误等问题
console.error('Error:', error);
});
请注意,这只是一个示例,具体的实现细节会根据使用的后端框架、数据库系统以及前端技术栈而有所不同。
正常情况下,在操作数据库之前就对数据进行校验了?
是的,通常在数据到达数据库之前,就应该在应用程序的业务逻辑层进行数据校验。这样做有几个好处:
-
减少无效请求:通过在应用层进行校验,可以避免无效的数据请求发送到数据库,减少数据库的负担。
-
提升用户体验:用户可以得到即时的反馈,而不需要等待服务器响应数据库错误。
-
安全性:防止不合法的数据到达数据库层,减少 SQL 注入等安全风险。
-
减少网络负担:如果数据在前端就被校验,可以避免无效数据的网络传输。
-
业务逻辑分离:将数据校验逻辑放在应用层可以保持业务逻辑的独立性,不依赖于数据库的约束。
-
多层校验:即便在应用层进行了数据校验,数据库层的约束也是必要的,它作为最后的保障确保数据的完整性和一致性。
数据校验通常包括前端校验和后端校验两个部分:
-
前端校验:在用户界面层进行,可以提供快速的反馈,减少不必要的服务器请求。常见的校验包括表单数据的格式、范围、是否必填等。
-
后端校验:在服务器端进行,是数据进入数据库前的最后一道防线。后端校验更加可靠,可以处理一些前端可能无法处理的复杂校验,也可以防止一些恶意用户绕过前端校验。
即使在应用程序层进行了彻底的校验,数据库层的约束依然是必要的,因为它们可以防止潜在的应用程序缺陷、配置错误或者安全漏洞导致的数据问题。此外,如果有多个应用�程序或服务访问同一个数据库,数据库层的约束可以保证所有应用程序都遵守相同的数据规则。
hstore 数据类型 使用场景
hstore 是 PostgreSQL 数据库中的一种数据类型,它用于存储一组键值对,类似于 Python 中的字典、Java 中的 Map 或者 JavaScript 中的对象。每个键和值都是字符串类型。hstore 数据类型非常灵活,适用于以下几种场景:
-
动态属性:当表中的某些列需要存储可变的属性集时,
hstore是一个很好的选择。例如,一个产品表可能有一些固定的列(如id,name,price),但是产品的其他属性(如颜色、尺寸、重量)可能因产品而异。这些动态属性可以存储在hstore列中。 -
半结构化数据:如果您需要存储半结构化的数据,即数据结构不固定或频灾示变,使用
hstore可以避免频繁地修改数据库表结构。 -
快速原型设计:在快速开发阶段,
hstore允许开发者存储和检索没有严格模式定义的数据,这有助于快速迭代和原型设计。 -
配置选项:存储配置选项或设置,每个键代表一个配置项,而值则代表该项的设置。
-
索引和搜索:
hstore类型的列可以被索引,这意味着您可以快速地搜索键或值,或者键值对。这对于某些类型的查询可能非常有用。 -
避免稀疏表:在有很多可选或不常用的��列时,使用
hstore可以避免创建拥有很多空值(NULL)的稀疏表。
需要注意的是,尽管 hstore 提供了很多灵活性,但它也有一些局限性:
- 类型限制:
hstore只能存储文本数据,如果需要存储其他类型的数据(如整数、浮点数、日期等),则需要在应用程序中进行类型转换。 - 性能考虑:使用
hstore可能会影响性能,特别是当存储大量数据或进行复杂查询时。并且,与普通列相比,hstore类型的操作通常更慢。 - 查询复杂性:查询
hstore数据可能比查询标准 SQL 列更复杂,这可能会使得 SQL 语句更难以编写和维护。
随着 JSONB 数据类型的引入,许多原本使用 hstore 的场景已经转向使用 JSONB,因为 JSONB 提供了更丰富的数据类型支持和更好的性能特性。不过,如果您只需要存储简单的键值对,并且对 JSONB 中的额外功能(如嵌套对象和数组)没有需求,hstore 仍然是一个有用的选项。
USING
DELETE FROM
basket a
USING basket b
WHERE
a.id < b.id
AND a.fruit = b.fruit;
-- 这里的USING 是啥意思
在这个 SQL 语句中,USING 关键字是用来指定一个 JOIN 操作的。DELETE FROM ... USING ... 是 PostgreSQL 特有的语法,它允许你在删除操作中使用一个 JOIN。这种语法通常用于删除表中的重复记录。
解释一下这个查询的逻辑:
basket a和basket b是同一个表basket的两个不同的别名,这样就可以在查询中将表与自己进行比较。a.id < b.id保证了只有id较小的行会被删除,这样可以避免删除所有重复的记录。因为如果两行是重复的(a.fruit = b.fruit),你只想保留一个(通常是id最大的那个)。a.fruit = b.fruit是删除条件,指定了哪些行是重复的。在这个例子中,如果两行的fruit列相同,则认为它们是重复的。
总的来说,这个查询的目的是删除 basket 表中所有有相同 fruit 值的重复记录,只保留每种 fruit 的 id 最大的记录。这是通过删除 id 较小的记录来实现的。
USING 自己是自连接
在您提供的 SQL 语句中,USING 关键字确实是用于创建一个自连接(self-join),即表 basket 与它自己连接。自连接是一种特殊类型的连接,表象似地与自己进行连接,但为了区分连接的两边,您需要为表的每一边使用不同的别名。在这个例子中,a 和 b 就是 basket 表的别名。
自连接通常用于比较同一个表中的行,或者根据同一个表中的其他行的值来筛选行。在您的例子中,自连接用于找到并删除那些具有相同 fruit 值但 id 较小的行,从而消除重复项。
这个查询使用了 DELETE 和 USING 来执行这个操作,这是 PostgreSQL 的特定语法。在其他数据库系统中,可能需要使用不同的方法来实现相同的结果,因为不是所有的数据库系统都支持这种语法。
example 子查询
SELECT department_id, name, salary
FROM employees e1
WHERE salary = (
SELECT MAX(salary)
FROM employees e2
WHERE e1.department_id = e2.department_id
);
这个语句 中 WHERE e1.department_id = e2.department_id ,我看不懂,为什么加它
这个 SQL 语句的目的是从 employees 表中为每个部门找到薪水最高的员工。在这个查询中,e1 和 e2 是 employees 表的两个不同的别名,它们被用来在同一个表的不同实例之间建立关联。
这里的关键在于子查询:
SELECT MAX(salary)
FROM employees e2
WHERE e1.department_id = e2.department_id
这个子查询的目的是为外部查询中正在考虑的每个员工(由 e1 表示)找到相同部门的最高薪水。WHERE e1.department_id = e2.department_id 这个条件确保了子查询只考虑和外部查询中同一部门的员工。这样,子查询返回的 MAX(salary) 就是当前 e1 表示的员工所在部门的最高薪水。
然后,外部查询通过条件 WHERE salary = (子查询) 筛选出那些薪水等于其所在部门最高薪水的员工。这意味着如果 e1 的 salary 与其部门内的最高薪水相等,这个员工就会被包含在最终结果中。
换句话说,这个查询的逻辑是:
- 对于
employees表中的每一行(每个员工),使用别名e1。 - 对于
e1当前指向的员工,执行子查询,找出e1所在部门的最高薪水。这里使用e2作为同一表的另一个实例的别名,以便能在子查询中引用department_id。 - 如果
e1的salary等于子查询找到的最高薪水,则选择这个e1行的department_id、name和salary。
这种查询模式是一种常见的 SQL 操作,用于解决各种“每组最大(或最小)”问题,即在分组的子集内寻找具有最大或最小值的记录。
唯一索引,唯一约束
唯一索引与唯一约束的区别
唯一索引(Unique Index)和唯一约束(Unique Constraint)都用于保证数据表中某一列或列组合的值是唯一的,不过它们在数据库中的实现和用途上有所区别。
唯一索引 (Unique Index)
- 性能优化:唯一索引不仅确保数据的唯一性,还可以提高查询性能。数据库系统可以利用唯一索引快速定位和检索数据。
- 物理实现:它是数据库中的一个物理对象,可以直接创建在数据表的一列或多列上。
- 灵活性:可以在不显式定义唯一约束的情况下创建唯一索引,这在某些情况下提供了更大的灵活性。
- 并发创建:在某些数据库系统中(如 PostgreSQL),可以使用
CONCURRENTLY关键字在不锁定表的情况下创建唯一索引,这对于需要高可用性的生产环境非常有用。
唯一约束 (Unique Constraint)
- 数据完整性:唯一约束通常用于实施业务规则和数据完整性,确保特定列或列组合中的数据值不会重复。
- 逻辑实现:它是数据库表的一个逻辑属性,通常在创建表或通过
ALTER TABLE语句显式添加到表中。 - 错误消息:在违反唯一约束时,数据库通常会提供标准的错误消息,有助于应用程序识别并处理数据完整性问题。
- 标准化:唯一约束是 SQL 标准的一部分,通常被视为表设计的一部分。
区别总结
尽管它们的最终目的相同,即确保数据的唯一性,但唯一索引通常更注重于性能优化和数据检索,而唯一约束更侧重于表达业务规则和数据完整性。在大多数数据库系统中,当你创建唯一约束时,数据库会自动创建一个唯一索引来支持这个约束。因此,二者在实践中常常是相互关联的。
从实现的角度来看,唯一约束是逻辑层面的约束,而唯一索引是物理层面的实现。在数据库设计时,通常会根据业务规则和性能需求来决定是使用唯一约束还是唯一索引,或者两者结合使用。
example
-- 使用唯一索引添加唯一约束 怎么理解
CREATE TABLE equipment (
id SERIAL PRIMARY KEY,
name VARCHAR (50) NOT NULL,
equip_id VARCHAR (16) NOT NULL
);
CREATE UNIQUE INDEX CONCURRENTLY equipment_equip_id
ON equipment (equip_id);
ALTER TABLE equipment
ADD CONSTRAINT unique_equip_id
UNIQUE USING INDEX equipment_equip_id;
在数据库中,唯一约束确保表中的所有数据在某一列或列组合上是唯一的,没有重复的值。这通常被用于确保数据的完整性,例如,确保每个用户的邮箱地址在用户表中是唯一的。
使用唯一索引来添加唯一约束是在创建表之后,通过创建一个�唯一索引来实施唯一性规则的一种方式。唯一索引不仅强制数据唯一性,还可以提高查询性能,因为索引允许数据库快速定位到特定的数据行。
你提供的 SQL 代码示例做了以下几步:
-
创建表: 首先,创建了一个名为
equipment的表,其中包含三个字段:id(主键)、name和equip_id。 -
创建唯一索引: 然后,使用
CREATE UNIQUE INDEX语句创建了一个名为equipment_equip_id的唯一索引,该索引针对equip_id字段。CONCURRENTLY关键字表示索引的创建将以并发方式进行,这样不会阻塞对表的读写操作。 -
添加唯一约束: 最后,使用
ALTER TABLE语句添加了一个唯一约束unique_equip_id,并指定使用之前创建的唯一索引equipment_equip_id来实施这个约束。这意味着equip_id字段的值在equipment表中必须是唯一的。
这里的关键是,唯一索引和唯一约束虽然都可以保证数据的唯一性,但它们是通过不同的方式实现的。唯一约束是一种表级约束,直接在表的定义中声明。而唯一索引是一种索引对象,它可以独立于表的定义存在,并且提供了查询优化的额外好处。
在你的示例中,唯一索引首先被创建,然后通过 ALTER TABLE 语句将这个索引转化为表级的唯一约束。这样做可以在不中断服务的情况下添加约束,因为创建索引的 CONCURRENTLY 选项允许索引在表上被创建而不锁定表对其他操作的访问。
最终表结构语句是怎样的
最终的表结构包括了一个唯一约束,但是在实际的 SQL 表定义中,唯一约束通常是隐含在创建索引的语句中的,而不会体现在最初的 CREATE TABLE 语句中。如果我们将所有的操作(包括创建表、创建索引、添加唯一约束)合并到一个表结构定义中,它将不会包含创建索引和添加约束的命令,因为这些是在表创建之后执行的。
但是,为了描述最终的表结构,我们可以在 CREATE TABLE 语句中直接包含唯一约束,如下所示:
CREATE TABLE equipment (
id SERIAL PRIMARY KEY, -- 'id' 列,自增序列,作为主键
name VARCHAR(50) NOT NULL, -- 'name' 列,最大长度为50的字符串,不能为空
equip_id VARCHAR(16) NOT NULL UNIQUE -- 'equip_id' 列,最大长度为16的字符串,不能为空,且是唯一的
);
在这个简化的表结构定义中,equip_id 列被直接定义为唯一的,这意味着数据库将自动为这个列创建一个唯一索引来保证其值的唯一性。这样,就不需要单独的索引创建和约束添加语句。
请注意,这个简化的定义假设我们没有使用并发索引创建的需求,且不需要单独的索引名称。在实际操作中,如果你需要并发创建索引或者指定索引名称,你仍然需要使用原始的步骤来创建索引和添加约束。
会进行全面备份
那有个问题了,如果看不到,假设某天我要备份数据库,会备份唯一索引 唯一约束吗? 当您备份数据库时,备份通常会包括数据库中所有的对象,包括表结构、索引、约束、视图、存储过程、触发器等。因此,无论是唯一索引还是唯一约束,都会被包含在备份中。备份并恢复数据库的目的就是要确保恢复后的数据库与备份时的状态完全一致。
大多数数据库管理系统提供了全面的备份和恢复功能。例如:
- 在 PostgreSQL 中,使用
pg_dump工具可以创建数据库的完整备份,包括所有表结构、索引和约束。 - 在 MySQL 中,
mysqldump工具用于创建数据库的备份,包括所�有的数据库对象和数据。 - 在 Microsoft SQL Server 中,
BACKUP DATABASE命令用于创建数据库的备份,其中包括了所有的数据库对象和数据。
备份操作不仅仅是复制数据文件,它还涉及记录数据库的元数据,这些元数据描述了数据库的结构和组织方式。因此,当您使用数据库管理系统提供的标准备份工具时,您可以放心,唯一索引和约束都会被包括在备份中,并且在恢复时将被正确地恢复到数据库中。
啥窗口函数?
https://www.postgresqltutorial.com/postgresql-tutorial/postgresql-explain/ https://www.postgresqltutorial.com/postgresql-window-function/
example
SELECT department_id, name, salary
FROM (
SELECT department_id, name, salary,
RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) as rank
FROM employees
) as ranked
WHERE rank = 1;
窗口函数(Window Functions)是 SQL 中的一种强大的功能,它允许在一个结果集的“窗口”上执行计算。这个“窗口”可以是相关联的行的集合,例如,所有来自同一个部门的行。窗口函数可以用来执行各种计算,如聚合、排名、行号等,而不需要把数据分组为独立的集合。
在您提供的 SQL 查询中,RANK() 是一个窗口函数,它被用来为每个部门内的员工基于其薪水进行排名。这个排名是在每个部门内部进行的,因为 OVER 子句中使用了 PARTITION BY department_id,它指示 SQL 引擎将 employees 表�中的行按 department_id 列的值进行分区。在每个这样的分区内部,ORDER BY salary DESC 指示 SQL 引擎按照 salary 降序排列行。
RANK() 函数为每个分区内的行分配一个排名,这个排名基于 salary 列的值。如果两行有相同的 salary 值,它们会得到相同的排名,而下一个排名值会留出空位(例如,如果有两个排名第一,下一个排名会是第三,而不是第二)。
整个查询的逻辑是这样的:
- 子查询首先选择
employees表的所有行,并使用RANK()窗口函数计算每个部门内基于salary的排名。 - 子查询的结果被放在一个临时的结果集中,这个结果集有一个别名
ranked。 - 外部查询从
ranked选择department_id、name和salary,但只有当rank列的值为 1 的时候,也就是说只选择每个部门薪水最高的员工。
这种方法通常比相关子查询(correlated subquery)更高效,因为它避免了对原始表的多次扫描。窗口函数只需要一次遍历表,就可以完成排名的计算。
不能理解,难道每一个部门的员工薪水都是从 rank 1 开始排的?
是的,您理解得正确。窗口函数 RANK() 在这里的使用确实是为了在每个部门内部对员工的薪水进行排名,而且这�个排名是从 1 开始的,对于每个部门都是独立进行的。
当您在 RANK() 函数中使用 PARTITION BY department_id 时,这意味着排名会在每个不同的 department_id 分区内重新开始。所以,每个部门内的员工都会根据他们的薪水被分配一个排名,这个排名是从 1 开始的,薪水最高的员工会被排在第一位。
例如,假设您有一个部门 A 和部门 B,每个部门都有三名员工,他们的薪水分别如下:
- 部门 A:员工 X($5000),员工 Y($6000),员工 Z($7000)
- 部门 B:员工 P($3000),员工 Q($4000),员工 R($5000)
当您使用 RANK() 函数时,结果将会是:
- 部门 A:员工 Z($7000,rank 1),员工 Y($6000,rank 2),员工 X($5000,rank 3)
- 部门 B:员工 R($5000,rank 1),员工 Q($4000,rank 2),员工 P($3000,rank 3)
最后,当您在外部查询中使用 WHERE rank = 1 时,您只会选择每个部门中排名第一的员工,即每个部门薪水最高的员工。在这个例子中,结果将包括部门 A 的员工 Z 和部门 B 的员工 R。
how run
example
SELECT
group_name,
AVG (price)
FROM
products
INNER JOIN product_groups USING (group_id)
GROUP BY
group_name;
-- 如何执行的
这个 SQL 查询是用来计算每个产品组的平均价格的。查询的执行步骤如下:
-
FROM products: 查询开始于从products表中选择数据。 -
INNER JOIN product_groups USING (group_id):products表通过group_id字段与product_groups表进行内连接(INNER JOIN)。内连接会合并两个表中的行,只保留两个表中都有匹配group_id的那些行。USING (group_id)是一个连接条件,它表明products表和product_groups表中用于连接的共同列是group_id。 -
SELECT group_name, AVG(price): 查询的选择列表包含两个列:group_name和price列的平均值。这里的group_name来自于product_groups表,而price来自于products表。 -
GROUP BY group_name: 这个GROUP BY子句指示数据库按照group_name列的值对结果集进行分组。每个不同的group_name值都会形成一个分组,对于每个分组,数据库将计算其price列值的平均值(AVG(price))。
总结一下,这个查询的执行过程是:
- 先通过
group_id将products表和product_groups表连接起来。 - 然后,按照
product_groups表中的group_name将结果集分组。 - 对于每个组,计算
products表中对应行的price列的平均值。 - 最后,选择每个产品组的名称和对应的平均价格。
查询的结果将是一个包含两列的列表,一列是 group_name,另一列是该组中所有产品的平均价格。